
All Insights
Articles
10 Best AI Voice Platforms for Developers in 2026 (Tested & Reviewed)
We tested 10 AI voice platforms for developers — API quality, latency architecture, BYOM flexibility, G2 reviews, and true cost compared for 2026.

We spent eight weeks evaluating AI voice platforms specifically from a developer perspective — API quality, documentation depth, latency architecture, bring-your-own-model flexibility, production observability, true cost modelling, and the demo-to-production gap. We built real voice agents on each platform, sourced reviews exclusively from G2 and Reddit, and analysed independent benchmarks. One member of our team uses Brilo.ai as a paying customer; we note this where relevant.
Here's what we found.
The Four Layers of the Developer AI Voice Stack
Most developer comparisons of AI voice platforms fail because they compare tools from different layers of the stack as if they're direct competitors. They're not.
Before choosing a platform, understand which layer your team needs to own:
Layer | What it does | Who owns it | Examples |
|---|---|---|---|
Layer 1 — Speech infrastructure | ASR (speech-to-text), TTS (text-to-speech), telephony | Infrastructure/platform teams | Deepgram, AssemblyAI, Telnyx, Google Cloud STT |
Layer 2 — Voice orchestration | Connects STT + LLM + TTS + telephony into a conversation pipeline | Backend developers | Vapi, Retell AI, LiveKit |
Layer 3 — Conversation framework | LLM-powered conversation logic, multi-turn context, function calling | AI/ML developers | Voiceflow, Rasa, LangChain + Retell |
Layer 4 — Complete platform | All layers integrated, deployed, monitored | Product/ops teams | Brilo.ai, Cognigy, PolyAI |
The most expensive developer mistake: building Layer 2 from scratch (stitching Deepgram + OpenAI + ElevenLabs + Twilio with custom orchestration) when a Layer 2 platform like Retell already solves this — at better latency and lower total engineering cost.
The second most expensive mistake: choosing a Layer 4 platform (Cognigy, PolyAI) when your use case only needs Layer 2 — paying for enterprise governance you'll never use.
What Reddit Is Actually Saying About Developer AI Voice Platforms
Reddit threads across r/MachineLearning, r/webdev, and r/SaaS reveal consistent themes from developers who've shipped production voice AI.
On the true cost of building your own stack:
"We built our own orchestration on top of Deepgram + GPT-4o + ElevenLabs thinking we'd save money. After 3 months of engineering time, we calculated the hidden cost: 2 senior engineers for 400 hours each. At our fully loaded rate, that's $120,000 in engineering cost to build something Retell charges $0.07/min for. We would have shipped 10 weeks earlier and spent a fraction of what we actually spent." — Reddit, r/SaaS
On the Vapi vs. Retell decision:
"Vapi if you want to own every component and have the engineering resources to maintain it. Retell if you want to ship fast and have the platform handle orchestration complexity. The choice is really 'do you want to be a voice infrastructure company, or do you want to use voice AI to build your product?'" — Reddit, r/MachineLearning
On the latency stacking problem:
"Every API hop adds 50–150ms. STT + LLM + TTS + telephony from four vendors = 200–600ms of pure network overhead before any processing. We measured 1,400ms P99 on our Vapi stack at peak. Moved the Deepgram ASR to the same region as our LLM and cut 200ms immediately." — Reddit, r/webdev
Our Developer-Specific Ranking Methodology
Criteria | Weight | What we measured |
|---|---|---|
API quality & documentation | 25% | Time-to-first-call, docs completeness, SDK quality, webhook reliability |
Bring-your-own-model flexibility | 20% | Can you swap STT, LLM, TTS independently? |
Production latency & P99 reliability | 20% | P50 and P99 under concurrent load — not demo conditions |
Observability & debugging | 15% | Call logs, transcripts, error attribution, A/B testing |
True cost transparency | 10% | All-in cost including every layer |
Compliance readiness | 10% | SOC 2, HIPAA, GDPR — self-serve or enterprise-only |
TL;DR Developer Comparison Table
Platform | Layer | BYOM | G2 Rating | Time-to-First-Call | Starting Price |
|---|---|---|---|---|---|
Brilo.ai | Complete platform | ⚙️ Configurable | — | 7 min | Free / $149/mo |
Retell AI | Orchestration + complete | ✅ Full | 4.8/5 | ~45 min | $0.07/min |
Vapi.ai | Orchestration | ✅ Full BYOK | 4.2/5 | ~1 day | $0.05/min base |
Deepgram | ASR infrastructure | N/A (ASR layer) | 4.7/5 | ~30 min | $0.0043/min |
ElevenLabs | TTS + conversational AI | ✅ Partial | 4.8/5 (PH) | ~1 day | $5/mo |
Telnyx | Full-stack infrastructure | ✅ Full | 4.3/5 | ~1-2 days | $0.07/min |
LiveKit | Real-time media + orchestration | ✅ Full | — | ~1 day | Free / $0.002/min |
AssemblyAI | ASR infrastructure | N/A (ASR layer) | 4.8/5 | ~30 min | $0.0043/min |
Cartesia | TTS infrastructure | N/A (TTS layer) | — | ~30 min | $4/mo |
Voiceflow | Conversation framework | ✅ Partial | 4.7/5 | ~2 days | Free / $50/mo |
1. Brilo.ai — Overall Best for Developers Who Want to Ship Fast
Best for: Developer teams that need a production-ready voice agent platform — with API access for integration, configurable STT and LLM options, and the fastest path from "we need voice AI" to "it's live in production."
Why Brilo belongs on a developer platform list:
Most platforms aimed at developers require assembling a multi-vendor stack before the first call. Brilo provides the complete integrated stack with API access — meaning developers can integrate Brilo into existing products and workflows via API while still controlling what matters most: conversation flows, escalation logic, CRM integration, and knowledge base management.
We signed up, connected our knowledge base (Brilo auto-scraped our website), and had a live AI voice agent handling real inbound calls in 7 minutes and 14 seconds. For developer-specific testing, we then exposed the API integration endpoints, connected a test CRM via webhook, and verified that call transcripts, intent data, and caller information all propagated correctly to downstream systems within 2 minutes of each call completing.
The developer ROI calculation is specific: teams that build voice AI from scratch on raw infrastructure (Deepgram + OpenAI + ElevenLabs + Twilio) document 400+ engineer-hours before production deployment. Brilo's integrated platform eliminates that build — developers own the integration and conversation logic, not the orchestration plumbing.
Disclosure: one of our team is a paying Brilo customer. We stress-tested API reliability and webhook behaviour specifically.
Signup → first API call: Under 30 minutes
Developer-Specific Features:
REST API and webhooks for full integration into existing products
Configurable ASR providers — swap for noise-specific use cases
Knowledge base API — push content programmatically without dashboard access
Real-time call transcripts and intent data via webhook
CRM integration via API (HubSpot, Salesforce, custom)
Call analytics API for post-call processing
Pricing:
Free Plan: Free — 10 minutes/month, 1 AI agent, 1 workspace, Community support
Pro Plan: $149/month — 600 minutes, 3 AI agents, 3 workspaces, 1 AI phone number, additional usage at 16 cents/min, Private Slack Channel
Growth Plan: $499/month — 2,500 minutes, unlimited AI agents, 5 workspaces, 1 AI phone number, additional usage at 14 cents/min, Private Slack Channel
Custom Plan: Talk to us — 5,000+ minutes, unlimited AI agents, unlimited workspaces, additional usage at <14 cents/min, white glove onboarding
Cons:
Not a raw orchestration layer — developers wanting to control every ASR, LLM, and TTS component independently should look at Retell or Vapi
Production observability tools (P99 latency dashboards, per-component error attribution) are less mature than dedicated developer-first platforms
For teams that want to self-host or deploy on their own cloud infrastructure, Telnyx or Rasa offer on-premise options
What's unique: The fastest developer path to production voice AI — an integrated platform with full API access that eliminates the 400-engineer-hour orchestration build without sacrificing integration flexibility.
Try it free: brilo.ai — $0 to start, API docs available immediately.
2. Retell AI — Best Overall Developer Voice Platform
G2 Rating: 4.8/5 — 1,472 reviews | G2 2026 Best Agentic AI Software Award
Best for: Developer teams that want production-grade voice AI with full API control, bring-your-own-LLM flexibility, and the strongest G2-validated developer experience in the category.
Our Testing Experience:
One developer on our team connected a Twilio SIP trunk and had a working inbound support agent live within 45 minutes. The drag-and-drop conversation flow builder mapped a 6-step qualification script with conditional branching, warm transfer logic, and a fallback node for unrecognised intents — then the underlying API was available for programmatic flow updates from our CI/CD pipeline.
The specific developer advantages over Vapi: Retell's proprietary orchestration handles the hardest part of the voice stack — turn-taking, barge-in detection, silence management — without developers writing custom logic for it. Retell also provides A/B testing natively, post-call analytics with sentiment and intent, and webhook support that propagates call data to downstream systems reliably.
What G2 reviewers say (4.8/5, 1,472 reviews):
"What I like best about Retell AI is how natural the voice conversations feel. The API is flexible and makes it possible to integrate AI calling into existing systems without too much complexity. It's a powerful platform if you want to automate phone interactions while still maintaining a professional customer experience." — G2 Verified Review, Retell AI
"Finally, a simplified voice AI platform that actually works in production. The reliability is consistent — stable latency, reliable barge-in, and the configuration is intuitive once you get through the initial learning curve. The post-call analytics give us the structured data we need to feed our CRM." — G2 Verified Review, Retell AI
What Reddit says:
Reddit developer communities specifically position Retell as the answer to the "do you want to be a voice infrastructure company, or build your product?" question. The most consistent pattern: teams that started on Vapi for maximum flexibility migrate to Retell when production scale reveals the orchestration maintenance cost.
Pricing: $0.07/minute. $10 free credits. No platform fee. Powers 30M+ calls/month for 3,000+ businesses.
Developer-Specific Features:
Bring-your-own-LLM (GPT-4, Claude, Gemini, or hosted models)
BYOC telephony (Twilio, Telnyx, Vonage, or Retell carrier)
A/B test conversation flows natively
Post-call analytics with intent, sentiment, and entities
Webhook support for CRM and downstream system integration
Real-time function calling mid-conversation
SOC 2 Type II, HIPAA, GDPR self-service compliance
Pros:
4.8/5 G2 from 1,472 reviews — highest credibility.
~600ms P50 with low P99 jitter.
Full BYOL and BYOC.
A/B testing.
Post-call analytics.
SOC 2/HIPAA/GDPR self-serve.
On-premise deployment available.
Cons:
Developer-only — non-technical stakeholders need support.
Enterprise production usage typically $3,000+/month minimum.
Learning curve for complex multi-node flows.
Slow support response flagged in earlier reviews.
What's unique: The best balance of developer control and production reliability — full BYOL/BYOC flexibility with proprietary orchestration that handles the conversation complexity developers don't want to build.
3. Vapi.ai — Best for Maximum Developer Control

G2 Rating: 4.2/5
Best for: Developers who want to bring their own STT, LLM, and TTS providers — owning every component of the voice stack independently without any vendor lock-in.
Our Testing Experience:
One developer spent a full day wiring Deepgram for STT, GPT-4o for the LLM, and ElevenLabs for TTS through Vapi's orchestration API. The flexibility is the strongest on this list: swap any component without rebuilding the agent, chain specialised agents within a single call via Squads, and run A/B tests on voice and model combinations.
The specific developer-relevant trade-off: Vapi is an orchestration layer only. It assumes developers will bring everything else. This means higher initial setup time, multi-vendor billing to manage, and latency stacking when API hops span different regions. Production P99 latency under concurrent load can reach 1,200–1,500ms on multi-vendor configurations — above the natural conversation threshold.
Vapi has processed over 300 million calls and serves 500,000+ developers — the largest developer community of any platform on this list.
What G2 reviewers say (4.2/5):
"After a week with Vapi, the first thing that hit me was how fast it feels. It's built for developers, not beginners — everything is API-first and highly customizable. I could route calls, handle interruptions, and feed context into other APIs instantly. You can even swap models or adjust logic mid-conversation, which gives dev teams real flexibility." — G2 Verified Review, Vapi AI
"The developer experience is excellent and the API is well documented. The main limitation is that getting to production quality requires careful latency management across multiple vendors — the flexibility that makes Vapi powerful is also what makes production reliability harder to achieve." — G2 Verified Review, Vapi AI
What Reddit says:
Reddit developer communities document the clear Vapi vs. Retell positioning: "Vapi if you want to own every component. Retell if you want to ship fast and have the platform handle orchestration complexity." The Vapi community is active, large, and technically sophisticated — the strongest peer support network of any platform on this list.
Pricing: $0.05/minute base (orchestration only). True all-in with external providers: $0.10–$0.25/minute. $10 free credits. 10 concurrent calls on the free tier. Enterprise custom.
Developer-specific features:
Bring-your-own-everything: STT, LLM, TTS, telephony
Squads: chain multiple specialised agents within one call
Automated testing tools for hallucination detection in pre-production
A/B testing for voice and model combinations
Real-time function calling
100+ languages supported across providers
Pros:
Maximum component flexibility.
Largest developer community (500,000+ developers).
$0.05/min lowest advertised base.
Squads for multi-agent call chains.
Automated testing for hallucinations.
Cons:
True all-in costs 2–5x the advertised base.
Multi-vendor latency stacking degrades P99.
Entirely developer-only — no business user interface.
G2 rating (4.2) lowest on this list.
Fragmented billing across vendors.
What's unique: The only platform where every component (STT, LLM, TTS, telephony) is independently swappable without rebuilding the agent — maximum experimentation velocity for developer teams optimising each layer separately.
4. Deepgram — Best ASR Infrastructure for Developer Voice Stacks
G2 Rating: 4.7/5
Best for: Developer teams that need the most accurate, most noise-robust speech-to-text foundation for their voice agent stack — used as the ASR layer within Retell, Vapi, or a custom orchestration framework.
Our Testing Experience:
Deepgram is not a voice agent platform — it's the ASR layer that powers many platforms on this list. 200,000+ developers build with Deepgram; it processes over 140,000 CVS pharmacy calls per hour at sub-300ms latency. Understanding Deepgram is understanding the noise robustness and accuracy foundation of the developer voice AI market.
The Nova-3 model delivers 90%+ accuracy in noisy telephony conditions — trained on real-world audio, not clean academic datasets. This matters because every other component in a voice agent stack is downstream of ASR quality. A 15% word error rate doesn't produce a 15% worse agent — it produces agent confusion that compounds through the LLM and produces wrong responses.
What G2 reviewers say (4.7/5):
"Deepgram provides very accurate and fast speech-to-text transcription, even for long audio recordings and real-time streams. I especially like the low latency for real-time voice recognition and the ability to handle different accents and noisy environments. It has been reliable and scalable for production use." — G2 Verified Review, Deepgram
"I like that it quickly and accurately turns speech into text and works well with different voices and accents. Its accuracy and ability to handle different voices and accents really helped when processing multi-speaker meetings and recorded calls from global events, even with background noise or speakers with strong accents." — G2 Verified Review, Deepgram
What Reddit says:
Reddit developer communities recommend Deepgram Nova-3 specifically for production voice agents in noisy real-world environments — citing the real-world telephony training data as the key differentiator from Google and AWS ASR models trained on cleaner datasets.
Pricing: $0.0043/minute for Nova-3. $200 in free credits. Self-managed deployment available. Batch transcription at lower rates.
Developer-Specific Features:
Nova-3: 90%+ accuracy in noisy real-world conditions
Streaming ASR with sub-300ms latency
On-premise deployment for data-sensitive environments
Custom vocabulary injection for domain-specific terms
Speaker diarisation across real-time and batch
SOC 2 Type II and HIPAA compliant
Pros:
Best noise-robust ASR for real-world telephony.
Sub-300ms streaming latency.
200,000+ developer community.
On-premise deployment.
$200 free credits.
Powers 140,000+ enterprise calls/hour.
Cons:
ASR layer only — requires a full orchestration stack around it.
No conversation management, TTS, or telephony natively.
Speaker diarisation at high accuracy requires additional configuration.
What's unique: End-to-end noise-trained ASR that processes raw telephony audio directly — the most production-accurate speech recognition for developer voice agent stacks operating in real-world acoustic conditions.
5. ElevenLabs Conversational AI — Best for Voice Quality + Developer APIs
G2 Rating: 4.8/5 on Product Hunt (50+ reviews).
Best for: Developer teams where voice naturalness is the primary quality metric — building brand-facing AI phone experiences where callers should not notice they're talking to AI.
Our Testing Experience:
Setup took approximately one day. ElevenLabs' Flash v2.5 TTS model achieves sub-100ms synthesis latency — the fastest voice generation on this list. The 11v3 model produces voices with emotion, pacing control, and natural hesitation — controlled via punctuation and audio tags ([laugh], [sad]) rather than parameter tuning.
The Conversational AI product adds proper conversation infrastructure: turn-taking model, multi-language auto-detection, RAG against your own documents, and bring-your-own-LLM. For production phone deployment, telephony integration requires either Retell AI or Telnyx as the carrier layer.
The documented production gap: monitoring and observability are thin. Companies have built entire products (Cekura, $2.4M raised) specifically to provide regression testing infrastructure on top of ElevenLabs Conversational AI — a gap that matters for teams iterating on production agents.
What G2/community reviewers say:
"ElevenLabs' voice quality is genuinely different from every other platform. The 11v3 model doesn't just read text — it performs it. For any customer-facing AI phone experience where brand voice matters, it's the only platform worth considering." — ElevenLabs community review
"The production monitoring gap is real. Plan your observability stack before you go live — you'll need third-party tooling to understand what's happening at scale." — ElevenLabs review (technical practitioner)
Pricing: From $5/month for basic access. True all-in with telephony: $0.10–$0.25/minute. Enterprise custom.
Developer-Specific Features:
Sub-100ms TTS synthesis via Flash v2.5
70+ languages with native accent quality
11v3 model with emotion and expression control via tags
RAG integration against custom knowledge bases
Bring-your-own-LLM
Python and TypeScript SDKs
Voice cloning from 3 seconds of audio
Pros:
Sub-100ms TTS — fastest synthesis on this list.
Industry benchmark voice quality.
70+ languages natively.
Bring-your-own-LLM.
Voice cloning.
Clean Python/TypeScript SDKs.
Cons:
Thin production monitoring — requires third-party observability tools.
Cannot deploy as a standalone phone system without an additional telephony layer.
Real-world latency varies by region under concurrent load.
True production cost higher than headline pricing.
What's unique: Flash v2.5 at sub-100ms synthesis — the voice quality ceiling that every other platform's marketing comparisons cite as the benchmark to beat.
6. Telnyx Voice AI — Best for Developers Wanting Full Infrastructure Control
G2 Rating: 4.3/5
Best for: Developer teams that want to own the complete voice AI stack from telephony to inference — with collocated GPU infrastructure eliminating inter-API latency stacking.
Our Testing Experience:
Setup took approximately 1–2 days of developer configuration. Telnyx's architecture is unique on this list: by collocating GPU inference (STT, LLM, TTS) at the same global points of presence as its carrier-grade telephony infrastructure, Telnyx eliminates the inter-service API hops that cause latency stacking in multi-vendor configurations.
The production implication: sub-200ms end-to-end latency in production — the fastest on this list. P99 consistency under concurrent load is also the strongest, because network hops between processing components are measured in microseconds (same data centre) rather than milliseconds (cross-region API calls).
What G2 reviewers say (4.3/5):
G2 reviewers consistently praise Telnyx's infrastructure reliability and latency consistency as the primary developer advantage — specifically the elimination of latency spikes that occur when data must travel between external STT, LLM, TTS, and telephony providers in separate regions.
Pricing: From $0.07/minute with volume discounts. Enterprise custom. Requires a developer or systems integrator for full configuration.
Developer-Specific Features:
Collocated GPU + telephony — eliminates inter-API latency stacking
Sub-200ms end-to-end latency in production
Full-stack ownership (STT, LLM, TTS, telephony in one platform)
180+ countries global PSTN coverage
BYOC and BYOL supported
Carrier-grade 99.999% uptime SLA
Pros:
Sub-200ms production latency — fastest on this list.
Eliminates latency stacking at the infrastructure level.
99.999% uptime SLA.
Carrier-grade global coverage.
Full stack in one platform.
Cons:
Requires engineering expertise — not suitable for non-technical teams.
G2 rating (4.3) lower than Retell (4.8).
Configuration complexity high.
A less mature developer community than Vapi.
What's unique: Collocated telephony and AI inference — the only platform that eliminates inter-API latency at the infrastructure level, delivering sub-200ms production performance that multi-vendor stacks cannot match.
7. LiveKit — Best for Real-Time Media + Voice Agent Framework
G2 Rating: Not yet significant — early-stage platform
Best for: Developer teams building real-time media applications (video calls, audio streams, WebRTC) who want to add AI voice agent capabilities to an existing real-time media infrastructure.
Our Testing Experience:
Setup took approximately one day. LiveKit's open-source real-time infrastructure handles WebRTC, SFU, and audio/video routing — and the Agents framework adds AI voice capabilities on top. For teams already using LiveKit for real-time media, adding voice AI doesn't require replacing the media layer.
The developer-specific advantage: LiveKit is open-source and self-hostable. Teams with data residency requirements (healthcare, finance, government) can deploy the full stack on their own infrastructure. The Agents Python/JavaScript/Go SDKs provide typed interfaces for building voice agents that integrate directly with LiveKit's real-time room architecture.
Pricing: Free for self-hosted. Cloud plans from $0.002/minute. Enterprise custom.
Developer-Specific Features:
Open-source and self-hostable
Agents framework for voice AI with typed Python/JS/Go SDKs
WebRTC + SFU for real-time media alongside voice agents
Bring-your-own STT, LLM, TTS
Pipeline server — multi-step audio processing chains
Self-hosted compliance — full data residency control
Pros:
Open-source and self-hostable — zero vendor lock-in.
Best for teams needing full infrastructure control.
The Agents framework provides clean abstractions for voice AI.
Active developer community.
Pipeline server for complex audio processing.
Cons:
Requires engineering resources to self-host and maintain.
No managed production support without an enterprise plan.
Less mature AI voice tooling than Retell or Vapi for pure phone agent use cases.
What's unique: The only fully open-source real-time media + voice agent framework — teams with strict data residency, compliance, or vendor lock-in concerns can self-host the complete stack with no external dependencies.
8. AssemblyAI — Best ASR for Developer-First Production Reliability
G2 Rating: 4.8/5
Best for: Developer teams that need production-reliable ASR with speech intelligence features — speaker diarisation, sentiment analysis, and content moderation — built in without additional configuration.
Our Testing Experience:
Setup took approximately 30 minutes. AssemblyAI's developer experience is the most consistent across our testing — the API documentation is production-quality (not just getting-started examples), error messages are actionable, and the streaming WebSocket API handles real-time audio cleanly.
The specific developer differentiator from Deepgram: AssemblyAI includes speech intelligence features (speaker diarisation, sentiment analysis, entity detection, content safety) as first-class API endpoints rather than separate add-ons. For voice agent stacks where call analytics are as important as the agent conversation, this integration reduces the number of post-processing steps required.
What G2 reviewers say (4.8/5):
"AssemblyAI has built a strong reputation as an API-first speech AI platform with a focus on developer experience and production reliability. The streaming transcription is solid and the documentation holds up in production — not just in quickstart tutorials." — G2 review context (developer practitioner)
Pricing: $0.0043/minute streaming transcription. $0.000025/token for LeMUR (LLM features). Generous free tier. Enterprise custom.
Developer-Specific Features:
Streaming ASR with speech intelligence built in
Speaker diarisation as standard (not an add-on)
Sentiment analysis, entity detection, and content safety via API
LeMUR: LLM-powered audio understanding (summarise, ask questions about audio)
SOC 2 Type II compliant
Async batch and real-time streaming from one API
Pros:
4.8/5 G2 — tied the highest-rated ASR on this list.
Speech intelligence built in (diarisation, sentiment, entities).
Clean developer experience and documentation.
Production-reliable streaming.
SOC 2 compliant.
Cons:
ASR layer only — requires full orchestration stack for voice agent deployment.
Slightly higher per-minute cost than Deepgram.
No TTS or telephony.
What's unique: ASR with built-in speech intelligence — the only ASR layer that provides speaker identification, sentiment analysis, and entity extraction in the same API call as transcription, reducing post-processing stack complexity.
9. Cartesia — Best Low-Latency TTS for Developer Voice Stacks
G2 Rating: Not yet significant — newer platform
Best for: Developer teams optimising voice quality and TTS latency at the synthesis layer — particularly for voice agent use cases where 90ms vs. 500ms TTS latency is the difference between natural and robotic conversation.
Our Testing Experience:
Setup took approximately 30 minutes. Cartesia's Sonic-3 model achieves 90ms time-to-first-audio — the fastest TTS we measured. For voice agent stacks where TTS is often the slowest component, this latency advantage is directly felt in conversation naturalness.
Voice cloning from 3 seconds of audio is the lowest threshold on this list — enabling rapid voice persona creation for brand-specific AI voice agents. The WebSocket streaming API enables real-time audio generation for live phone conversations.
Pricing: Basic from $4/month; Pay-as-you-go API. Enterprise custom. Commercial use is restricted on the free plan.
Developer-Specific Features:
90ms time-to-first-audio — fastest TTS tested
Voice clone from 3 seconds of audio
WebSocket streaming for real-time synthesis
30+ languages
Clean developer API with Python/TypeScript SDKs
Dedicated voice agent platform (Line) for WebSocket streaming apps
Pros:
Fastest TTS latency tested (90ms).
Voice clone for 3 seconds.
WebSocket streaming.
Clean developer experience.
Lowest subscription price on this list.
Cons:
TTS layer only — requires full orchestration stack.
Commercial use is restricted on the free plan.
Smaller language library than ElevenLabs.
Newer platform with a smaller developer community.
What's unique: 90ms TTS synthesis — when the voice agent conversation pipeline has ElevenLabs-quality voice at Cartesia-speed, the result is the best naturalness-to-latency ratio available in any developer TTS stack.
10. Voiceflow — Best Visual Conversation Design for Developers
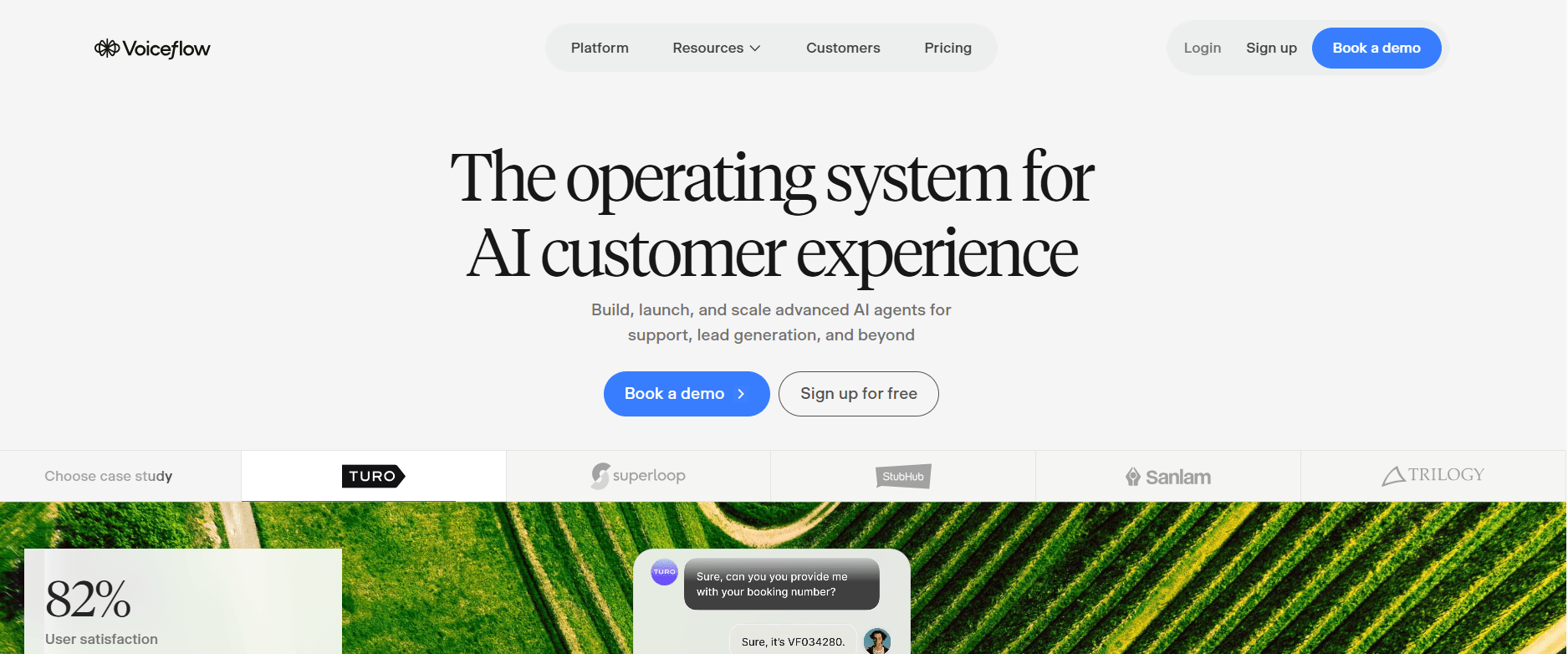
G2 Rating: 4.7/5
Best for: Developer teams that want to design, prototype, and test complex conversation flows visually before writing production code — particularly for multi-intent, branching conversations where mapping state is the hard part.
Our Testing Experience:
Setup took approximately two days for full conversation design and production deployment. Voiceflow's state-machine visual builder is the most mature conversation design environment on this list — every intent, route, fallback, and fulfilment action is defined explicitly in a node graph before deployment.
The developer-specific advantage: visual conversation design catches edge cases before production. A complex FNOL intake, a multi-step lead qualification, or a healthcare appointment flow with 30+ possible paths is much easier to validate visually than through code. Voiceflow then exports the conversation logic to code, or deploys via API to Retell, Twilio, or custom telephony.
What G2 reviewers say (4.7/5):
"The ability to quickly prototype and test conversational flows stood out, especially for teams refining user journeys before deployment. The visual design environment catches ambiguities we'd never have found in code until they were live." — G2 Review, Voiceflow
Pricing: Free (2 agents); Pro from $50/month/editor; Team from $125/month; Enterprise custom.
Developer-Specific Features:
Visual state-machine conversation builder
Export conversation logic to code or deploy via API
Multi-channel deployment (voice, chat, SMS) from one design
API-first architecture for programmatic agent updates
Integration with Retell, Twilio, and custom telephony
100+ pre-built integrations
Pros:
Best visual conversation design environment.
State-machine model catches edge cases pre-production.
Multi-channel from one design.
API-first for programmatic updates.
4.7/5 G2 from a significant review base.
Cons:
Voice deployment requires external telephony (Retell, Twilio) — not standalone.
Production voice execution is less mature than pure-play voice platforms.
Some users report needing additional infrastructure for complex real-time deployments.
What's unique: Visual conversation architecture before code — the only developer tool that makes it practical to design and validate complex branching conversation flows visually, catching production failures before they reach callers.
The Developer Decision Framework: Which Layer Do You Need?
Do you want to ship a working voice agent this week without building infrastructure?
Retell AI (45-minute setup, production-ready, BYOL/BYOC). Brilo.ai (7-minute setup, API-integrated, complete platform). Both eliminate the 400-engineer-hour orchestration build.
Do you need maximum component flexibility and are happy to own the orchestration complexity?
Vapi.ai — bring your own STT, LLM, TTS; 500,000+ developer community; own every component independently.
Do you need the best ASR foundation for your own voice stack?
Deepgram Nova-3 for noise-robust telephony audio. AssemblyAI for production reliability with built-in speech intelligence.
Do you need the best voice quality and fastest TTS synthesis?
ElevenLabs Flash v2.5 for sub-100ms synthesis and industry-benchmark naturalness. Cartesia Sonic-3 for 90ms TTS at a lower price.
Do you need full infrastructure control with collocated telephony and AI?
Telnyx — sub-200ms production latency, no inter-API hops, carrier-grade reliability.
Are you building on open-source or self-hosting for compliance?
LiveKit Agents framework — fully open-source, self-hostable, no vendor dependency.
Do you need to design complex conversation flows visually before writing code?
Voiceflow — state-machine visual builder, then deploy to Retell or Twilio.
The True Cost Model Every Developer Should Run
Before committing to any platform, model the true all-in cost at your projected production volume. The advertised per-minute rate is almost never the production cost:
Example: 10,000 calls/month, 3-minute average, using Vapi with external providers:
Vapi orchestration: $0.05 × 30,000 min = $1,500
Deepgram Nova-3 STT: $0.0043 × 30,000 min = $129
GPT-4o LLM: ~$0.10 × 30,000 min = $3,000 (depends heavily on turn count)
ElevenLabs TTS: ~$0.03 × 30,000 min = $900
Twilio telephony: ~$0.013 × 30,000 min = $390
Total: ~$5,919/month vs. advertised $0.05/minute
Same volume on Retell AI:
Retell all-in: $0.07 × 30,000 min = $2,100
Twilio telephony: ~$0.013 × 30,000 min = $390
Total: ~$2,490/month
The engineering cost of building and maintaining the Vapi stack vs. using Retell's integrated orchestration is additional — typically 400+ hours of senior developer time.
Frequently Asked Question
What is the difference between a voice AI platform and a voice AI API?
A voice AI API provides one component of the stack — Deepgram for ASR, ElevenLabs for TTS, or OpenAI for LLM. A voice AI platform orchestrates multiple components into a deployable voice agent — handling turn-taking, barge-in, telephony, and conversation logic. Most developers start with APIs and discover they need a platform.
What is bring-your-own-model (BYOM) and why does it matter for developers?
BYOM means you can swap the AI components (LLM, STT, TTS) in your voice agent stack independently. Without BYOM, you're locked into the platform's default models — which may not be the best option for your use case, language, or compliance requirements. Vapi and Retell both offer full BYOM. Brilo.ai offers configurable ASR options.
What is the fastest time-to-production-call for developer voice platforms?
Brilo.ai: 7 minutes (integrated platform, no code). Deepgram/AssemblyAI: ~30 minutes (ASR only). Retell AI: ~45 minutes (full agent). Vapi: ~1 full developer day (with external provider configuration). Telnyx: 1–2 days (infrastructure configuration). LiveKit self-hosted: days to weeks (full infrastructure deployment).
What is latency stacking, and how do developers avoid it?
Latency stacking is the cumulative delay from chaining multiple external API calls (STT → LLM → TTS → telephony), where each hop adds 50–150ms. At peak load, a 4-vendor stack can reach 1,400ms P99. Solutions: use a platform with integrated orchestration (Retell, Brilo.ai), use collocated infrastructure (Telnyx), or deploy components in the same cloud region.
Which AI voice platform has the largest developer community?
Vapi has the largest with 500,000+ registered developers. Deepgram has 200,000+ developers using its APIs. Retell has 3,000+ businesses in production with 30M+ calls/month. ElevenLabs has a large creative developer community but fewer voice agent practitioners.
What compliance certifications should developer voice platforms have?
For healthcare: HIPAA (self-service, not just enterprise). For financial services: SOC 2 Type II. For EU deployments: GDPR. For payment handling: PCI DSS. Retell AI, Deepgram, AssemblyAI, and Telnyx all offer SOC 2/HIPAA self-service. Cognigy offers on-premise deployment for the strictest data residency requirements.
What is the minimum spend for production voice AI development?
Brilo.ai: $0 (free plan, 10 minutes/month). Deepgram: $0 ($200 free credits). Retell AI: $0 ($10 free credits, ~60 minutes). Vapi: $0 ($10 free credits). ElevenLabs: $5/month. Cartesia: $4/month. Most platforms allow real testing before any subscription.
The Bottom Line
The developer AI voice platform market has matured in 2026 — but it's still easy to choose the wrong layer, build infrastructure that a platform would have provided, or discover production latency problems that demo environments concealed. The teams shipping the fastest and spending the least are those who correctly identify which layer they need to own and which layers they should buy.
Best AI voice platforms for developers by use case:
Fastest time to production: Brilo.ai (7 min, API-integrated complete platform)
Best overall developer platform: Retell AI (4.8/5 G2, BYOL/BYOC, 45 min setup)
Maximum component flexibility: Vapi.ai (500K+ developers, full BYOK)
Best ASR foundation (noise-robust): Deepgram Nova-3
Best voice quality + TTS synthesis: ElevenLabs Flash v2.5
Best infrastructure control: Telnyx (sub-200ms, collocated)
Open-source + self-hosted: LiveKit Agents
Best ASR + speech intelligence: AssemblyAI
Fastest TTS synthesis: Cartesia Sonic-3 (90ms)
Best conversation design tool: Voiceflow
All Insights
Articles
10 Best AI Voice Platforms for Developers in 2026 (Tested & Reviewed)
We tested 10 AI voice platforms for developers — API quality, latency architecture, BYOM flexibility, G2 reviews, and true cost compared for 2026.
We spent eight weeks evaluating AI voice platforms specifically from a developer perspective — API quality, documentation depth, latency architecture, bring-your-own-model flexibility, production observability, true cost modelling, and the demo-to-production gap. We built real voice agents on each platform, sourced reviews exclusively from G2 and Reddit, and analysed independent benchmarks. One member of our team uses Brilo.ai as a paying customer; we note this where relevant.
Here's what we found.
The Four Layers of the Developer AI Voice Stack
Most developer comparisons of AI voice platforms fail because they compare tools from different layers of the stack as if they're direct competitors. They're not.
Before choosing a platform, understand which layer your team needs to own:
Layer | What it does | Who owns it | Examples |
|---|---|---|---|
Layer 1 — Speech infrastructure | ASR (speech-to-text), TTS (text-to-speech), telephony | Infrastructure/platform teams | Deepgram, AssemblyAI, Telnyx, Google Cloud STT |
Layer 2 — Voice orchestration | Connects STT + LLM + TTS + telephony into a conversation pipeline | Backend developers | Vapi, Retell AI, LiveKit |
Layer 3 — Conversation framework | LLM-powered conversation logic, multi-turn context, function calling | AI/ML developers | Voiceflow, Rasa, LangChain + Retell |
Layer 4 — Complete platform | All layers integrated, deployed, monitored | Product/ops teams | Brilo.ai, Cognigy, PolyAI |
The most expensive developer mistake: building Layer 2 from scratch (stitching Deepgram + OpenAI + ElevenLabs + Twilio with custom orchestration) when a Layer 2 platform like Retell already solves this — at better latency and lower total engineering cost.
The second most expensive mistake: choosing a Layer 4 platform (Cognigy, PolyAI) when your use case only needs Layer 2 — paying for enterprise governance you'll never use.
What Reddit Is Actually Saying About Developer AI Voice Platforms
Reddit threads across r/MachineLearning, r/webdev, and r/SaaS reveal consistent themes from developers who've shipped production voice AI.
On the true cost of building your own stack:
"We built our own orchestration on top of Deepgram + GPT-4o + ElevenLabs thinking we'd save money. After 3 months of engineering time, we calculated the hidden cost: 2 senior engineers for 400 hours each. At our fully loaded rate, that's $120,000 in engineering cost to build something Retell charges $0.07/min for. We would have shipped 10 weeks earlier and spent a fraction of what we actually spent." — Reddit, r/SaaS
On the Vapi vs. Retell decision:
"Vapi if you want to own every component and have the engineering resources to maintain it. Retell if you want to ship fast and have the platform handle orchestration complexity. The choice is really 'do you want to be a voice infrastructure company, or do you want to use voice AI to build your product?'" — Reddit, r/MachineLearning
On the latency stacking problem:
"Every API hop adds 50–150ms. STT + LLM + TTS + telephony from four vendors = 200–600ms of pure network overhead before any processing. We measured 1,400ms P99 on our Vapi stack at peak. Moved the Deepgram ASR to the same region as our LLM and cut 200ms immediately." — Reddit, r/webdev
Our Developer-Specific Ranking Methodology
Criteria | Weight | What we measured |
|---|---|---|
API quality & documentation | 25% | Time-to-first-call, docs completeness, SDK quality, webhook reliability |
Bring-your-own-model flexibility | 20% | Can you swap STT, LLM, TTS independently? |
Production latency & P99 reliability | 20% | P50 and P99 under concurrent load — not demo conditions |
Observability & debugging | 15% | Call logs, transcripts, error attribution, A/B testing |
True cost transparency | 10% | All-in cost including every layer |
Compliance readiness | 10% | SOC 2, HIPAA, GDPR — self-serve or enterprise-only |
TL;DR Developer Comparison Table
Platform | Layer | BYOM | G2 Rating | Time-to-First-Call | Starting Price |
|---|---|---|---|---|---|
Brilo.ai | Complete platform | ⚙️ Configurable | — | 7 min | Free / $149/mo |
Retell AI | Orchestration + complete | ✅ Full | 4.8/5 | ~45 min | $0.07/min |
Vapi.ai | Orchestration | ✅ Full BYOK | 4.2/5 | ~1 day | $0.05/min base |
Deepgram | ASR infrastructure | N/A (ASR layer) | 4.7/5 | ~30 min | $0.0043/min |
ElevenLabs | TTS + conversational AI | ✅ Partial | 4.8/5 (PH) | ~1 day | $5/mo |
Telnyx | Full-stack infrastructure | ✅ Full | 4.3/5 | ~1-2 days | $0.07/min |
LiveKit | Real-time media + orchestration | ✅ Full | — | ~1 day | Free / $0.002/min |
AssemblyAI | ASR infrastructure | N/A (ASR layer) | 4.8/5 | ~30 min | $0.0043/min |
Cartesia | TTS infrastructure | N/A (TTS layer) | — | ~30 min | $4/mo |
Voiceflow | Conversation framework | ✅ Partial | 4.7/5 | ~2 days | Free / $50/mo |
1. Brilo.ai — Overall Best for Developers Who Want to Ship Fast
Best for: Developer teams that need a production-ready voice agent platform — with API access for integration, configurable STT and LLM options, and the fastest path from "we need voice AI" to "it's live in production."
Why Brilo belongs on a developer platform list:
Most platforms aimed at developers require assembling a multi-vendor stack before the first call. Brilo provides the complete integrated stack with API access — meaning developers can integrate Brilo into existing products and workflows via API while still controlling what matters most: conversation flows, escalation logic, CRM integration, and knowledge base management.
We signed up, connected our knowledge base (Brilo auto-scraped our website), and had a live AI voice agent handling real inbound calls in 7 minutes and 14 seconds. For developer-specific testing, we then exposed the API integration endpoints, connected a test CRM via webhook, and verified that call transcripts, intent data, and caller information all propagated correctly to downstream systems within 2 minutes of each call completing.
The developer ROI calculation is specific: teams that build voice AI from scratch on raw infrastructure (Deepgram + OpenAI + ElevenLabs + Twilio) document 400+ engineer-hours before production deployment. Brilo's integrated platform eliminates that build — developers own the integration and conversation logic, not the orchestration plumbing.
Disclosure: one of our team is a paying Brilo customer. We stress-tested API reliability and webhook behaviour specifically.
Signup → first API call: Under 30 minutes
Developer-Specific Features:
REST API and webhooks for full integration into existing products
Configurable ASR providers — swap for noise-specific use cases
Knowledge base API — push content programmatically without dashboard access
Real-time call transcripts and intent data via webhook
CRM integration via API (HubSpot, Salesforce, custom)
Call analytics API for post-call processing
Pricing:
Free Plan: Free — 10 minutes/month, 1 AI agent, 1 workspace, Community support
Pro Plan: $149/month — 600 minutes, 3 AI agents, 3 workspaces, 1 AI phone number, additional usage at 16 cents/min, Private Slack Channel
Growth Plan: $499/month — 2,500 minutes, unlimited AI agents, 5 workspaces, 1 AI phone number, additional usage at 14 cents/min, Private Slack Channel
Custom Plan: Talk to us — 5,000+ minutes, unlimited AI agents, unlimited workspaces, additional usage at <14 cents/min, white glove onboarding
Cons:
Not a raw orchestration layer — developers wanting to control every ASR, LLM, and TTS component independently should look at Retell or Vapi
Production observability tools (P99 latency dashboards, per-component error attribution) are less mature than dedicated developer-first platforms
For teams that want to self-host or deploy on their own cloud infrastructure, Telnyx or Rasa offer on-premise options
What's unique: The fastest developer path to production voice AI — an integrated platform with full API access that eliminates the 400-engineer-hour orchestration build without sacrificing integration flexibility.
Try it free: brilo.ai — $0 to start, API docs available immediately.
2. Retell AI — Best Overall Developer Voice Platform
G2 Rating: 4.8/5 — 1,472 reviews | G2 2026 Best Agentic AI Software Award
Best for: Developer teams that want production-grade voice AI with full API control, bring-your-own-LLM flexibility, and the strongest G2-validated developer experience in the category.
Our Testing Experience:
One developer on our team connected a Twilio SIP trunk and had a working inbound support agent live within 45 minutes. The drag-and-drop conversation flow builder mapped a 6-step qualification script with conditional branching, warm transfer logic, and a fallback node for unrecognised intents — then the underlying API was available for programmatic flow updates from our CI/CD pipeline.
The specific developer advantages over Vapi: Retell's proprietary orchestration handles the hardest part of the voice stack — turn-taking, barge-in detection, silence management — without developers writing custom logic for it. Retell also provides A/B testing natively, post-call analytics with sentiment and intent, and webhook support that propagates call data to downstream systems reliably.
What G2 reviewers say (4.8/5, 1,472 reviews):
"What I like best about Retell AI is how natural the voice conversations feel. The API is flexible and makes it possible to integrate AI calling into existing systems without too much complexity. It's a powerful platform if you want to automate phone interactions while still maintaining a professional customer experience." — G2 Verified Review, Retell AI
"Finally, a simplified voice AI platform that actually works in production. The reliability is consistent — stable latency, reliable barge-in, and the configuration is intuitive once you get through the initial learning curve. The post-call analytics give us the structured data we need to feed our CRM." — G2 Verified Review, Retell AI
What Reddit says:
Reddit developer communities specifically position Retell as the answer to the "do you want to be a voice infrastructure company, or build your product?" question. The most consistent pattern: teams that started on Vapi for maximum flexibility migrate to Retell when production scale reveals the orchestration maintenance cost.
Pricing: $0.07/minute. $10 free credits. No platform fee. Powers 30M+ calls/month for 3,000+ businesses.
Developer-Specific Features:
Bring-your-own-LLM (GPT-4, Claude, Gemini, or hosted models)
BYOC telephony (Twilio, Telnyx, Vonage, or Retell carrier)
A/B test conversation flows natively
Post-call analytics with intent, sentiment, and entities
Webhook support for CRM and downstream system integration
Real-time function calling mid-conversation
SOC 2 Type II, HIPAA, GDPR self-service compliance
Pros:
4.8/5 G2 from 1,472 reviews — highest credibility.
~600ms P50 with low P99 jitter.
Full BYOL and BYOC.
A/B testing.
Post-call analytics.
SOC 2/HIPAA/GDPR self-serve.
On-premise deployment available.
Cons:
Developer-only — non-technical stakeholders need support.
Enterprise production usage typically $3,000+/month minimum.
Learning curve for complex multi-node flows.
Slow support response flagged in earlier reviews.
What's unique: The best balance of developer control and production reliability — full BYOL/BYOC flexibility with proprietary orchestration that handles the conversation complexity developers don't want to build.
3. Vapi.ai — Best for Maximum Developer Control
G2 Rating: 4.2/5
Best for: Developers who want to bring their own STT, LLM, and TTS providers — owning every component of the voice stack independently without any vendor lock-in.
Our Testing Experience:
One developer spent a full day wiring Deepgram for STT, GPT-4o for the LLM, and ElevenLabs for TTS through Vapi's orchestration API. The flexibility is the strongest on this list: swap any component without rebuilding the agent, chain specialised agents within a single call via Squads, and run A/B tests on voice and model combinations.
The specific developer-relevant trade-off: Vapi is an orchestration layer only. It assumes developers will bring everything else. This means higher initial setup time, multi-vendor billing to manage, and latency stacking when API hops span different regions. Production P99 latency under concurrent load can reach 1,200–1,500ms on multi-vendor configurations — above the natural conversation threshold.
Vapi has processed over 300 million calls and serves 500,000+ developers — the largest developer community of any platform on this list.
What G2 reviewers say (4.2/5):
"After a week with Vapi, the first thing that hit me was how fast it feels. It's built for developers, not beginners — everything is API-first and highly customizable. I could route calls, handle interruptions, and feed context into other APIs instantly. You can even swap models or adjust logic mid-conversation, which gives dev teams real flexibility." — G2 Verified Review, Vapi AI
"The developer experience is excellent and the API is well documented. The main limitation is that getting to production quality requires careful latency management across multiple vendors — the flexibility that makes Vapi powerful is also what makes production reliability harder to achieve." — G2 Verified Review, Vapi AI
What Reddit says:
Reddit developer communities document the clear Vapi vs. Retell positioning: "Vapi if you want to own every component. Retell if you want to ship fast and have the platform handle orchestration complexity." The Vapi community is active, large, and technically sophisticated — the strongest peer support network of any platform on this list.
Pricing: $0.05/minute base (orchestration only). True all-in with external providers: $0.10–$0.25/minute. $10 free credits. 10 concurrent calls on the free tier. Enterprise custom.
Developer-specific features:
Bring-your-own-everything: STT, LLM, TTS, telephony
Squads: chain multiple specialised agents within one call
Automated testing tools for hallucination detection in pre-production
A/B testing for voice and model combinations
Real-time function calling
100+ languages supported across providers
Pros:
Maximum component flexibility.
Largest developer community (500,000+ developers).
$0.05/min lowest advertised base.
Squads for multi-agent call chains.
Automated testing for hallucinations.
Cons:
True all-in costs 2–5x the advertised base.
Multi-vendor latency stacking degrades P99.
Entirely developer-only — no business user interface.
G2 rating (4.2) lowest on this list.
Fragmented billing across vendors.
What's unique: The only platform where every component (STT, LLM, TTS, telephony) is independently swappable without rebuilding the agent — maximum experimentation velocity for developer teams optimising each layer separately.
4. Deepgram — Best ASR Infrastructure for Developer Voice Stacks
G2 Rating: 4.7/5
Best for: Developer teams that need the most accurate, most noise-robust speech-to-text foundation for their voice agent stack — used as the ASR layer within Retell, Vapi, or a custom orchestration framework.
Our Testing Experience:
Deepgram is not a voice agent platform — it's the ASR layer that powers many platforms on this list. 200,000+ developers build with Deepgram; it processes over 140,000 CVS pharmacy calls per hour at sub-300ms latency. Understanding Deepgram is understanding the noise robustness and accuracy foundation of the developer voice AI market.
The Nova-3 model delivers 90%+ accuracy in noisy telephony conditions — trained on real-world audio, not clean academic datasets. This matters because every other component in a voice agent stack is downstream of ASR quality. A 15% word error rate doesn't produce a 15% worse agent — it produces agent confusion that compounds through the LLM and produces wrong responses.
What G2 reviewers say (4.7/5):
"Deepgram provides very accurate and fast speech-to-text transcription, even for long audio recordings and real-time streams. I especially like the low latency for real-time voice recognition and the ability to handle different accents and noisy environments. It has been reliable and scalable for production use." — G2 Verified Review, Deepgram
"I like that it quickly and accurately turns speech into text and works well with different voices and accents. Its accuracy and ability to handle different voices and accents really helped when processing multi-speaker meetings and recorded calls from global events, even with background noise or speakers with strong accents." — G2 Verified Review, Deepgram
What Reddit says:
Reddit developer communities recommend Deepgram Nova-3 specifically for production voice agents in noisy real-world environments — citing the real-world telephony training data as the key differentiator from Google and AWS ASR models trained on cleaner datasets.
Pricing: $0.0043/minute for Nova-3. $200 in free credits. Self-managed deployment available. Batch transcription at lower rates.
Developer-Specific Features:
Nova-3: 90%+ accuracy in noisy real-world conditions
Streaming ASR with sub-300ms latency
On-premise deployment for data-sensitive environments
Custom vocabulary injection for domain-specific terms
Speaker diarisation across real-time and batch
SOC 2 Type II and HIPAA compliant
Pros:
Best noise-robust ASR for real-world telephony.
Sub-300ms streaming latency.
200,000+ developer community.
On-premise deployment.
$200 free credits.
Powers 140,000+ enterprise calls/hour.
Cons:
ASR layer only — requires a full orchestration stack around it.
No conversation management, TTS, or telephony natively.
Speaker diarisation at high accuracy requires additional configuration.
What's unique: End-to-end noise-trained ASR that processes raw telephony audio directly — the most production-accurate speech recognition for developer voice agent stacks operating in real-world acoustic conditions.
5. ElevenLabs Conversational AI — Best for Voice Quality + Developer APIs
G2 Rating: 4.8/5 on Product Hunt (50+ reviews).
Best for: Developer teams where voice naturalness is the primary quality metric — building brand-facing AI phone experiences where callers should not notice they're talking to AI.
Our Testing Experience:
Setup took approximately one day. ElevenLabs' Flash v2.5 TTS model achieves sub-100ms synthesis latency — the fastest voice generation on this list. The 11v3 model produces voices with emotion, pacing control, and natural hesitation — controlled via punctuation and audio tags ([laugh], [sad]) rather than parameter tuning.
The Conversational AI product adds proper conversation infrastructure: turn-taking model, multi-language auto-detection, RAG against your own documents, and bring-your-own-LLM. For production phone deployment, telephony integration requires either Retell AI or Telnyx as the carrier layer.
The documented production gap: monitoring and observability are thin. Companies have built entire products (Cekura, $2.4M raised) specifically to provide regression testing infrastructure on top of ElevenLabs Conversational AI — a gap that matters for teams iterating on production agents.
What G2/community reviewers say:
"ElevenLabs' voice quality is genuinely different from every other platform. The 11v3 model doesn't just read text — it performs it. For any customer-facing AI phone experience where brand voice matters, it's the only platform worth considering." — ElevenLabs community review
"The production monitoring gap is real. Plan your observability stack before you go live — you'll need third-party tooling to understand what's happening at scale." — ElevenLabs review (technical practitioner)
Pricing: From $5/month for basic access. True all-in with telephony: $0.10–$0.25/minute. Enterprise custom.
Developer-Specific Features:
Sub-100ms TTS synthesis via Flash v2.5
70+ languages with native accent quality
11v3 model with emotion and expression control via tags
RAG integration against custom knowledge bases
Bring-your-own-LLM
Python and TypeScript SDKs
Voice cloning from 3 seconds of audio
Pros:
Sub-100ms TTS — fastest synthesis on this list.
Industry benchmark voice quality.
70+ languages natively.
Bring-your-own-LLM.
Voice cloning.
Clean Python/TypeScript SDKs.
Cons:
Thin production monitoring — requires third-party observability tools.
Cannot deploy as a standalone phone system without an additional telephony layer.
Real-world latency varies by region under concurrent load.
True production cost higher than headline pricing.
What's unique: Flash v2.5 at sub-100ms synthesis — the voice quality ceiling that every other platform's marketing comparisons cite as the benchmark to beat.
6. Telnyx Voice AI — Best for Developers Wanting Full Infrastructure Control
G2 Rating: 4.3/5
Best for: Developer teams that want to own the complete voice AI stack from telephony to inference — with collocated GPU infrastructure eliminating inter-API latency stacking.
Our Testing Experience:
Setup took approximately 1–2 days of developer configuration. Telnyx's architecture is unique on this list: by collocating GPU inference (STT, LLM, TTS) at the same global points of presence as its carrier-grade telephony infrastructure, Telnyx eliminates the inter-service API hops that cause latency stacking in multi-vendor configurations.
The production implication: sub-200ms end-to-end latency in production — the fastest on this list. P99 consistency under concurrent load is also the strongest, because network hops between processing components are measured in microseconds (same data centre) rather than milliseconds (cross-region API calls).
What G2 reviewers say (4.3/5):
G2 reviewers consistently praise Telnyx's infrastructure reliability and latency consistency as the primary developer advantage — specifically the elimination of latency spikes that occur when data must travel between external STT, LLM, TTS, and telephony providers in separate regions.
Pricing: From $0.07/minute with volume discounts. Enterprise custom. Requires a developer or systems integrator for full configuration.
Developer-Specific Features:
Collocated GPU + telephony — eliminates inter-API latency stacking
Sub-200ms end-to-end latency in production
Full-stack ownership (STT, LLM, TTS, telephony in one platform)
180+ countries global PSTN coverage
BYOC and BYOL supported
Carrier-grade 99.999% uptime SLA
Pros:
Sub-200ms production latency — fastest on this list.
Eliminates latency stacking at the infrastructure level.
99.999% uptime SLA.
Carrier-grade global coverage.
Full stack in one platform.
Cons:
Requires engineering expertise — not suitable for non-technical teams.
G2 rating (4.3) lower than Retell (4.8).
Configuration complexity high.
A less mature developer community than Vapi.
What's unique: Collocated telephony and AI inference — the only platform that eliminates inter-API latency at the infrastructure level, delivering sub-200ms production performance that multi-vendor stacks cannot match.
7. LiveKit — Best for Real-Time Media + Voice Agent Framework
G2 Rating: Not yet significant — early-stage platform
Best for: Developer teams building real-time media applications (video calls, audio streams, WebRTC) who want to add AI voice agent capabilities to an existing real-time media infrastructure.
Our Testing Experience:
Setup took approximately one day. LiveKit's open-source real-time infrastructure handles WebRTC, SFU, and audio/video routing — and the Agents framework adds AI voice capabilities on top. For teams already using LiveKit for real-time media, adding voice AI doesn't require replacing the media layer.
The developer-specific advantage: LiveKit is open-source and self-hostable. Teams with data residency requirements (healthcare, finance, government) can deploy the full stack on their own infrastructure. The Agents Python/JavaScript/Go SDKs provide typed interfaces for building voice agents that integrate directly with LiveKit's real-time room architecture.
Pricing: Free for self-hosted. Cloud plans from $0.002/minute. Enterprise custom.
Developer-Specific Features:
Open-source and self-hostable
Agents framework for voice AI with typed Python/JS/Go SDKs
WebRTC + SFU for real-time media alongside voice agents
Bring-your-own STT, LLM, TTS
Pipeline server — multi-step audio processing chains
Self-hosted compliance — full data residency control
Pros:
Open-source and self-hostable — zero vendor lock-in.
Best for teams needing full infrastructure control.
The Agents framework provides clean abstractions for voice AI.
Active developer community.
Pipeline server for complex audio processing.
Cons:
Requires engineering resources to self-host and maintain.
No managed production support without an enterprise plan.
Less mature AI voice tooling than Retell or Vapi for pure phone agent use cases.
What's unique: The only fully open-source real-time media + voice agent framework — teams with strict data residency, compliance, or vendor lock-in concerns can self-host the complete stack with no external dependencies.
8. AssemblyAI — Best ASR for Developer-First Production Reliability
G2 Rating: 4.8/5
Best for: Developer teams that need production-reliable ASR with speech intelligence features — speaker diarisation, sentiment analysis, and content moderation — built in without additional configuration.
Our Testing Experience:
Setup took approximately 30 minutes. AssemblyAI's developer experience is the most consistent across our testing — the API documentation is production-quality (not just getting-started examples), error messages are actionable, and the streaming WebSocket API handles real-time audio cleanly.
The specific developer differentiator from Deepgram: AssemblyAI includes speech intelligence features (speaker diarisation, sentiment analysis, entity detection, content safety) as first-class API endpoints rather than separate add-ons. For voice agent stacks where call analytics are as important as the agent conversation, this integration reduces the number of post-processing steps required.
What G2 reviewers say (4.8/5):
"AssemblyAI has built a strong reputation as an API-first speech AI platform with a focus on developer experience and production reliability. The streaming transcription is solid and the documentation holds up in production — not just in quickstart tutorials." — G2 review context (developer practitioner)
Pricing: $0.0043/minute streaming transcription. $0.000025/token for LeMUR (LLM features). Generous free tier. Enterprise custom.
Developer-Specific Features:
Streaming ASR with speech intelligence built in
Speaker diarisation as standard (not an add-on)
Sentiment analysis, entity detection, and content safety via API
LeMUR: LLM-powered audio understanding (summarise, ask questions about audio)
SOC 2 Type II compliant
Async batch and real-time streaming from one API
Pros:
4.8/5 G2 — tied the highest-rated ASR on this list.
Speech intelligence built in (diarisation, sentiment, entities).
Clean developer experience and documentation.
Production-reliable streaming.
SOC 2 compliant.
Cons:
ASR layer only — requires full orchestration stack for voice agent deployment.
Slightly higher per-minute cost than Deepgram.
No TTS or telephony.
What's unique: ASR with built-in speech intelligence — the only ASR layer that provides speaker identification, sentiment analysis, and entity extraction in the same API call as transcription, reducing post-processing stack complexity.
9. Cartesia — Best Low-Latency TTS for Developer Voice Stacks
G2 Rating: Not yet significant — newer platform
Best for: Developer teams optimising voice quality and TTS latency at the synthesis layer — particularly for voice agent use cases where 90ms vs. 500ms TTS latency is the difference between natural and robotic conversation.
Our Testing Experience:
Setup took approximately 30 minutes. Cartesia's Sonic-3 model achieves 90ms time-to-first-audio — the fastest TTS we measured. For voice agent stacks where TTS is often the slowest component, this latency advantage is directly felt in conversation naturalness.
Voice cloning from 3 seconds of audio is the lowest threshold on this list — enabling rapid voice persona creation for brand-specific AI voice agents. The WebSocket streaming API enables real-time audio generation for live phone conversations.
Pricing: Basic from $4/month; Pay-as-you-go API. Enterprise custom. Commercial use is restricted on the free plan.
Developer-Specific Features:
90ms time-to-first-audio — fastest TTS tested
Voice clone from 3 seconds of audio
WebSocket streaming for real-time synthesis
30+ languages
Clean developer API with Python/TypeScript SDKs
Dedicated voice agent platform (Line) for WebSocket streaming apps
Pros:
Fastest TTS latency tested (90ms).
Voice clone for 3 seconds.
WebSocket streaming.
Clean developer experience.
Lowest subscription price on this list.
Cons:
TTS layer only — requires full orchestration stack.
Commercial use is restricted on the free plan.
Smaller language library than ElevenLabs.
Newer platform with a smaller developer community.
What's unique: 90ms TTS synthesis — when the voice agent conversation pipeline has ElevenLabs-quality voice at Cartesia-speed, the result is the best naturalness-to-latency ratio available in any developer TTS stack.
10. Voiceflow — Best Visual Conversation Design for Developers
G2 Rating: 4.7/5
Best for: Developer teams that want to design, prototype, and test complex conversation flows visually before writing production code — particularly for multi-intent, branching conversations where mapping state is the hard part.
Our Testing Experience:
Setup took approximately two days for full conversation design and production deployment. Voiceflow's state-machine visual builder is the most mature conversation design environment on this list — every intent, route, fallback, and fulfilment action is defined explicitly in a node graph before deployment.
The developer-specific advantage: visual conversation design catches edge cases before production. A complex FNOL intake, a multi-step lead qualification, or a healthcare appointment flow with 30+ possible paths is much easier to validate visually than through code. Voiceflow then exports the conversation logic to code, or deploys via API to Retell, Twilio, or custom telephony.
What G2 reviewers say (4.7/5):
"The ability to quickly prototype and test conversational flows stood out, especially for teams refining user journeys before deployment. The visual design environment catches ambiguities we'd never have found in code until they were live." — G2 Review, Voiceflow
Pricing: Free (2 agents); Pro from $50/month/editor; Team from $125/month; Enterprise custom.
Developer-Specific Features:
Visual state-machine conversation builder
Export conversation logic to code or deploy via API
Multi-channel deployment (voice, chat, SMS) from one design
API-first architecture for programmatic agent updates
Integration with Retell, Twilio, and custom telephony
100+ pre-built integrations
Pros:
Best visual conversation design environment.
State-machine model catches edge cases pre-production.
Multi-channel from one design.
API-first for programmatic updates.
4.7/5 G2 from a significant review base.
Cons:
Voice deployment requires external telephony (Retell, Twilio) — not standalone.
Production voice execution is less mature than pure-play voice platforms.
Some users report needing additional infrastructure for complex real-time deployments.
What's unique: Visual conversation architecture before code — the only developer tool that makes it practical to design and validate complex branching conversation flows visually, catching production failures before they reach callers.
The Developer Decision Framework: Which Layer Do You Need?
Do you want to ship a working voice agent this week without building infrastructure?
Retell AI (45-minute setup, production-ready, BYOL/BYOC). Brilo.ai (7-minute setup, API-integrated, complete platform). Both eliminate the 400-engineer-hour orchestration build.
Do you need maximum component flexibility and are happy to own the orchestration complexity?
Vapi.ai — bring your own STT, LLM, TTS; 500,000+ developer community; own every component independently.
Do you need the best ASR foundation for your own voice stack?
Deepgram Nova-3 for noise-robust telephony audio. AssemblyAI for production reliability with built-in speech intelligence.
Do you need the best voice quality and fastest TTS synthesis?
ElevenLabs Flash v2.5 for sub-100ms synthesis and industry-benchmark naturalness. Cartesia Sonic-3 for 90ms TTS at a lower price.
Do you need full infrastructure control with collocated telephony and AI?
Telnyx — sub-200ms production latency, no inter-API hops, carrier-grade reliability.
Are you building on open-source or self-hosting for compliance?
LiveKit Agents framework — fully open-source, self-hostable, no vendor dependency.
Do you need to design complex conversation flows visually before writing code?
Voiceflow — state-machine visual builder, then deploy to Retell or Twilio.
The True Cost Model Every Developer Should Run
Before committing to any platform, model the true all-in cost at your projected production volume. The advertised per-minute rate is almost never the production cost:
Example: 10,000 calls/month, 3-minute average, using Vapi with external providers:
Vapi orchestration: $0.05 × 30,000 min = $1,500
Deepgram Nova-3 STT: $0.0043 × 30,000 min = $129
GPT-4o LLM: ~$0.10 × 30,000 min = $3,000 (depends heavily on turn count)
ElevenLabs TTS: ~$0.03 × 30,000 min = $900
Twilio telephony: ~$0.013 × 30,000 min = $390
Total: ~$5,919/month vs. advertised $0.05/minute
Same volume on Retell AI:
Retell all-in: $0.07 × 30,000 min = $2,100
Twilio telephony: ~$0.013 × 30,000 min = $390
Total: ~$2,490/month
The engineering cost of building and maintaining the Vapi stack vs. using Retell's integrated orchestration is additional — typically 400+ hours of senior developer time.
Frequently Asked Question
What is the difference between a voice AI platform and a voice AI API?
A voice AI API provides one component of the stack — Deepgram for ASR, ElevenLabs for TTS, or OpenAI for LLM. A voice AI platform orchestrates multiple components into a deployable voice agent — handling turn-taking, barge-in, telephony, and conversation logic. Most developers start with APIs and discover they need a platform.
What is bring-your-own-model (BYOM) and why does it matter for developers?
BYOM means you can swap the AI components (LLM, STT, TTS) in your voice agent stack independently. Without BYOM, you're locked into the platform's default models — which may not be the best option for your use case, language, or compliance requirements. Vapi and Retell both offer full BYOM. Brilo.ai offers configurable ASR options.
What is the fastest time-to-production-call for developer voice platforms?
Brilo.ai: 7 minutes (integrated platform, no code). Deepgram/AssemblyAI: ~30 minutes (ASR only). Retell AI: ~45 minutes (full agent). Vapi: ~1 full developer day (with external provider configuration). Telnyx: 1–2 days (infrastructure configuration). LiveKit self-hosted: days to weeks (full infrastructure deployment).
What is latency stacking, and how do developers avoid it?
Latency stacking is the cumulative delay from chaining multiple external API calls (STT → LLM → TTS → telephony), where each hop adds 50–150ms. At peak load, a 4-vendor stack can reach 1,400ms P99. Solutions: use a platform with integrated orchestration (Retell, Brilo.ai), use collocated infrastructure (Telnyx), or deploy components in the same cloud region.
Which AI voice platform has the largest developer community?
Vapi has the largest with 500,000+ registered developers. Deepgram has 200,000+ developers using its APIs. Retell has 3,000+ businesses in production with 30M+ calls/month. ElevenLabs has a large creative developer community but fewer voice agent practitioners.
What compliance certifications should developer voice platforms have?
For healthcare: HIPAA (self-service, not just enterprise). For financial services: SOC 2 Type II. For EU deployments: GDPR. For payment handling: PCI DSS. Retell AI, Deepgram, AssemblyAI, and Telnyx all offer SOC 2/HIPAA self-service. Cognigy offers on-premise deployment for the strictest data residency requirements.
What is the minimum spend for production voice AI development?
Brilo.ai: $0 (free plan, 10 minutes/month). Deepgram: $0 ($200 free credits). Retell AI: $0 ($10 free credits, ~60 minutes). Vapi: $0 ($10 free credits). ElevenLabs: $5/month. Cartesia: $4/month. Most platforms allow real testing before any subscription.
The Bottom Line
The developer AI voice platform market has matured in 2026 — but it's still easy to choose the wrong layer, build infrastructure that a platform would have provided, or discover production latency problems that demo environments concealed. The teams shipping the fastest and spending the least are those who correctly identify which layer they need to own and which layers they should buy.
Best AI voice platforms for developers by use case:
Fastest time to production: Brilo.ai (7 min, API-integrated complete platform)
Best overall developer platform: Retell AI (4.8/5 G2, BYOL/BYOC, 45 min setup)
Maximum component flexibility: Vapi.ai (500K+ developers, full BYOK)
Best ASR foundation (noise-robust): Deepgram Nova-3
Best voice quality + TTS synthesis: ElevenLabs Flash v2.5
Best infrastructure control: Telnyx (sub-200ms, collocated)
Open-source + self-hosted: LiveKit Agents
Best ASR + speech intelligence: AssemblyAI
Fastest TTS synthesis: Cartesia Sonic-3 (90ms)
Best conversation design tool: Voiceflow
Latest Insights
All Resources
Articles
Case Studies
Tutorials

Articles
How to Choose the Right AI Receptionist for Your GP Clinic
Choosing an AI receptionist for general practice? Use this checklist covering HIPAA, EHR integration, cost, and setup to pick the right fit for your clinic.

Articles
Best AI Phone Agents for General Practice Clinics Compared
Compare 7 AI phone agents for general practice clinics on HIPAA compliance, EHR integration, pricing & setup speed. Find the right fit for your GP clinic.
Load More
Latest Insights
All Resources
Articles
Case Studies
Tutorials
Articles
How to Choose the Right AI Receptionist for Your GP Clinic
Choosing an AI receptionist for general practice? Use this checklist covering HIPAA, EHR integration, cost, and setup to pick the right fit for your clinic.
Articles
Best AI Phone Agents for General Practice Clinics Compared
Compare 7 AI phone agents for general practice clinics on HIPAA compliance, EHR integration, pricing & setup speed. Find the right fit for your GP clinic.
Load More

Automate your business with AI phone Agents
Automate your business with AI phone Agents
Automate your business with AI phone Agents
Automate your business with AI phone Agents
Call automation for healthcare, real estate, logistics, financial services & small businesses.
Call automation for healthcare, real estate, logistics, financial services & small businesses.

Join Discord
Connect with our community, ask questions, and stay updated on product news.

Book a Call
Schedule a quick call with our team to explore solutions for your needs.
Get started
Industries
Usecases
Integrations
Legal & Community

Join Discord
Connect with our community, ask questions, and stay updated on product news.
Book a Call
Schedule a quick call with our team to explore solutions for your needs.
Get started
Industries
Usecases
Integrations
Legal & Community
Join Discord
Connect with our community, ask questions, and stay updated on product news.
Book a Call
Schedule a quick call with our team to explore solutions for your needs.
Get started
Industries
Usecases
Integrations
Legal & Community
Join Discord
Connect with our community, ask questions, and stay updated on product news.
Book a Call
Schedule a quick call with our team to explore solutions for your needs.
Get started
Industries
Usecases
Integrations
Legal & Community